今回のポストは「適切に運用された Entra ID テナント上で、適切に運用された組織アカウントで開発をしている方」や Entra ID テナントの闇(テナント複数あったりマイクロソフトアカウントが入り混じったり)に触れたことのない人には縁のない話です。この文章だけで痛みが分かる方には有益な情報を追記したつもりなので、引き続き通読してください。「タイトルみたいな複雑な運用するのが間違っている」という方へのアドバイスはこちらになります。
今回私がハマった元ネタは以下の記事に記載のある「Cosmos DB へのデータアクセスを RBAC で制御しようとした」です。本来はハマりどころは大してないのですが、掲題の件が絡むと厄介なネタが増えてきます。
learn.microsoft.com
今回は「以下のすべてに該当しない人」は読む必要はありませんが、どこかでは引っかかる人が多いと思います。最初の項目だけなら大して問題にならないのですが、二・三・四つ目が混じってくると Entra ID の複雑さが猛威をふるってくるので、この辺りはノウハウをまとめた方が良いなと思ったのでこちらで紹介します。
- 自端末でのローカル開発をする
- Entra ID が複数あり guest invite を利用している
- 利用しているアカウントが組織アカウントでなくマイクロソフトアカウント
- むしろ組織アカウントとマイクロソフトアカウントが入り混じって自分の環境で利用している
今回はそれぞれで節を区切って「こういう風に試したらこう上手くいった(または失敗した)」をそれぞれ紹介します。
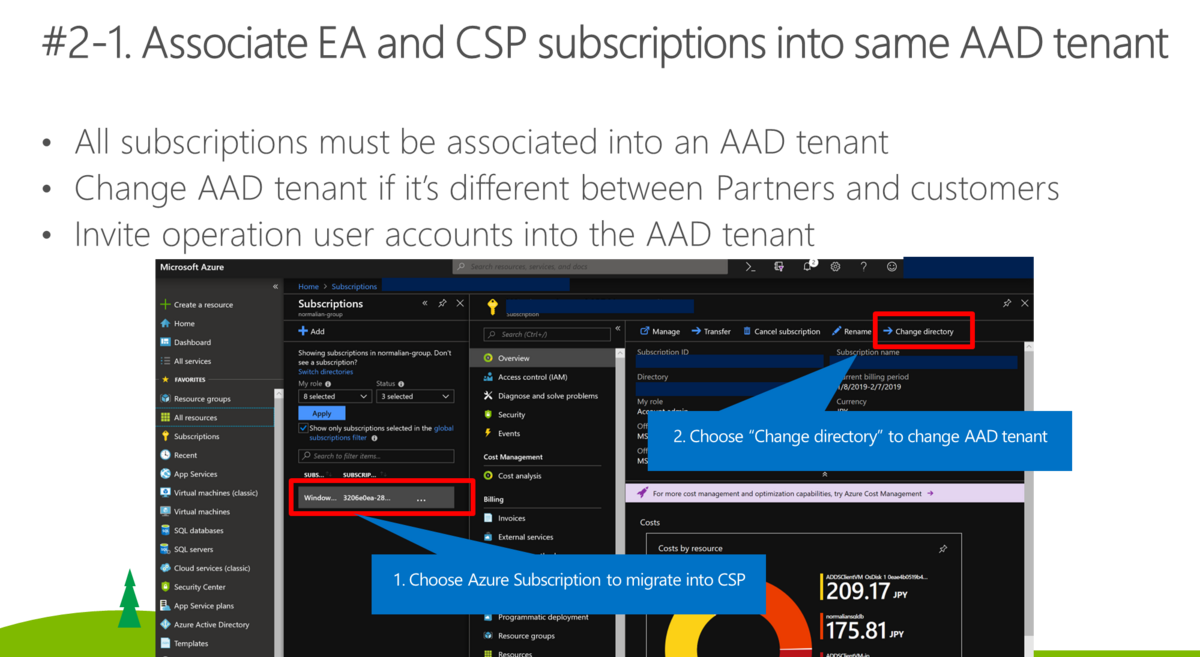
EntraID テナントが一つ、同 EntraID テナントにサブスクリプションが存在し、同 EntraID テナントの組織アカウントを使う場合(上手くいくケース)
念のため、公式ドキュメントでも紹介されているこちらの復習をしましょう。こちらは図に表すと以下になります。
![]()
CosmosDB の場合、リソース制御向けの built-in role はあってもデータアクセス向けの built-in role は無いので、まずはこちらをカスタムロールとして作成します。今回はデータの読み込み・書き込み・削除も想定して以下の JSONとしました。
{"RoleName": "CosmosDBDataAccessRole",
"Type": "CustomRole",
"AssignableScopes": ["/"],
"Permissions": [{"DataActions": ["Microsoft.DocumentDB/databaseAccounts/readMetadata",
"Microsoft.DocumentDB/databaseAccounts/sqlDatabases/containers/items/*",
"Microsoft.DocumentDB/databaseAccounts/sqlDatabases/containers/*"
]}]}次にこちらのカスタムロールを自分の CosmosDB 向けに Azure 上に作成します。ここで出力されるカスタムロールのリソースIDである "XXXXXXX-XXX-XXX-XXXX-XXXXXXXXX"は後で使います(実際はUUIDのランダムな値が出力されます)。
$rgName = "your-resource-group-name"
$cosmosdbName = "your-cosmosdb-name"
az cosmosdb sql role definition create -a $cosmosdbName -g $rgName -b role-definition-rw.json
{
"assignableScopes": [
"/subscriptions/your-subscription-id/resourceGroups/your-resource-group-name/providers/Microsoft.DocumentDB/databaseAccounts/your-cosmosdb-name"
],
"id": "/subscriptions/your-subscription-id/resourceGroups/your-resource-group-name/providers/Microsoft.DocumentDB/databaseAccounts/your-cosmosdb-name/sqlRoleDefinitions/XXXXXXX-XXX-XXX-XXXX-XXXXXXXXX",
"name": "XXXXXXX-XXX-XXX-XXXX-XXXXXXXXX",
"permissions": [
{
"dataActions": [
"Microsoft.DocumentDB/databaseAccounts/readMetadata",
"Microsoft.DocumentDB/databaseAccounts/sqlDatabases/containers/items/*",
"Microsoft.DocumentDB/databaseAccounts/sqlDatabases/containers/*"
],
"notDataActions": []
}
],
"resourceGroup": "your-resource-group-name",
"roleName": "CosmosDBDataAccessRole",
"type": "Microsoft.DocumentDB/databaseAccounts/sqlRoleDefinitions",
"typePropertiesType": "CustomRole"
}次に自身の組織アカウントの ID を得ます。以下の az ad user show コマンドを実行します。
az ad user show --id "myuser@normalian.xxx"
{
"@odata.context": "https://graph.microsoft.com/v1.0/$metadata#users/$entity",
"businessPhones": [],
"displayName": "aduser-normalian",
"givenName": "aduser",
"id": "YYYYYYY-YYY-YYY-YYYY-YYYYYYYYY",
"jobTitle": "Principal Administrator",
"mail": "myuser@normalian.xxx",
"mobilePhone": null,
"officeLocation": null,
"preferredLanguage": null,
"surname": "normalian",
"userPrincipalName": "myuser@normalian.xxx"
}最後に作成したカスタムロールを当該ユーザに割り当てて終了です。
$ az cosmosdb sql role assignment create -a $cosmosdbName -g $rgName -p "YYYYYYY-YYY-YYY-YYYY-YYYYYYYYY" -d "XXXXXXX-XXX-XXX-XXXX-XXXXXXXXX" -s "/"
{
"id": "/subscriptions/your-subscription-id/resourceGroups/your-resource-group-name/providers/Microsoft.DocumentDB/databaseAccounts/your-cosmosdb-name/sqlRoleAssignments/787a36f9-
a7f3-40c8-a860-99d4c6ae5fd9",
"name": "787a36f9-a7f3-40c8-a860-99d4c6ae5fd9",
"principalId": "b0bde25a-d588-410c-a16d-30fc001661c4",
"resourceGroup": "your-resource-group-name",
"roleDefinitionId": "/subscriptions/your-subscription-id/resourceGroups/your-resource-group-name/providers/Microsoft.DocumentDB/databaseAccounts/your-cosmosdb-name/sqlRoleDefinit
ions/26eeca83-1fd8-4f40-8a5e-b66dac7d3e08",
"scope": "/subscriptions/your-subscription-id/resourceGroups/your-resource-group-name/providers/Microsoft.DocumentDB/databaseAccounts/your-cosmosdb-name",
"type": "Microsoft.DocumentDB/databaseAccounts/sqlRoleAssignments"
}最後に C#側のソースコードで当該ユーザの認証情報を利用します。少しだけ抜粋すると以下になりますが、詳細は
Use system-assigned managed identities to access Azure Cosmos DB data | Microsoft Learnの記事を参照すると良いでしょう。組織アカウントを活用した secret string を利用しないアクセスが可能になります。
using Azure.Identity;
using Microsoft.Azure.Cosmos;
var builder = WebApplication.CreateBuilder(args);
// Add services to the container.
builder.Services.AddControllersWithViews();
builder.Services.AddSingleton<CosmosClient>(serviceProvider =>
{
return new CosmosClient(
accountEndpoint: builder.Configuration["AZURE_COSMOS_DB_NOSQL_ENDPOINT"]!,
tokenCredential: new DefaultAzureCredential()
);
});
var app = builder.Build();こちらに関しては原理さえ理解していれば特にハマりどころはないでしょう。
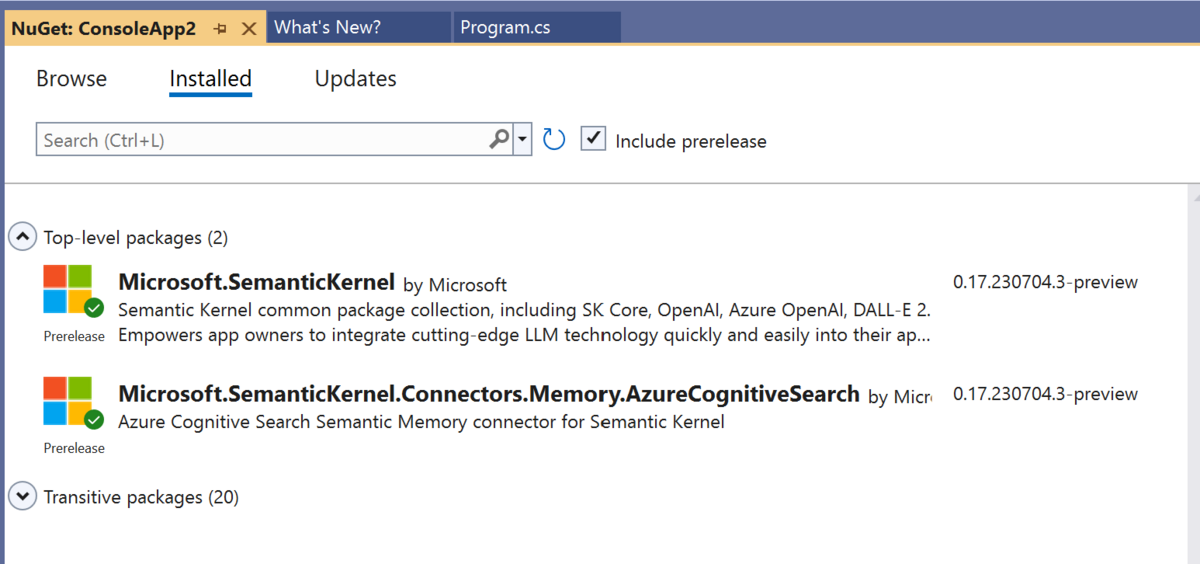
EntraID テナントが二つ以上存在し、サブスクリプションと組織アカウントの EntraID テナントが異なる場合(一応上手くいくケース)
ここからはややこしい例を挙げていきたいと思います。大きな会社に限らずで良くある構成だと思いますが、本番環境の EntraID に組織アカウントが登録されているが、guest invite で開発用の EntraID に当該組織アカウントが招待され、開発用の EntraID 配下の Azure subscription を利用する場合です。図に表すと以下になります。
![]()
この場合に大事なポイントは以下の二つになります。
- どうやって guest invitation されたアカウントにカスタムロールを割り当てるのか?
- DefaultAzureCredential で認証される Entra ID テナント(本番環境相当)を 開発用の EntraID に指定するか
一つ目に関しては割とシンプルです。念のためですが、何も考えずに guest user 招待したユーザを入力すると以下の様になります。
$ az ad user show --id "myuser01@normalian.xxx"
az : ERROR: Resource 'myuser01@normalian.xxx' does not exist or one of its queried reference-property objects are not present.
At line:1 char:1
+ az ad user show --id "myuser01@normalian.xxx"
+ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+ CategoryInfo : NotSpecified: (ERROR: Resource...re not present.:String) [], RemoteException
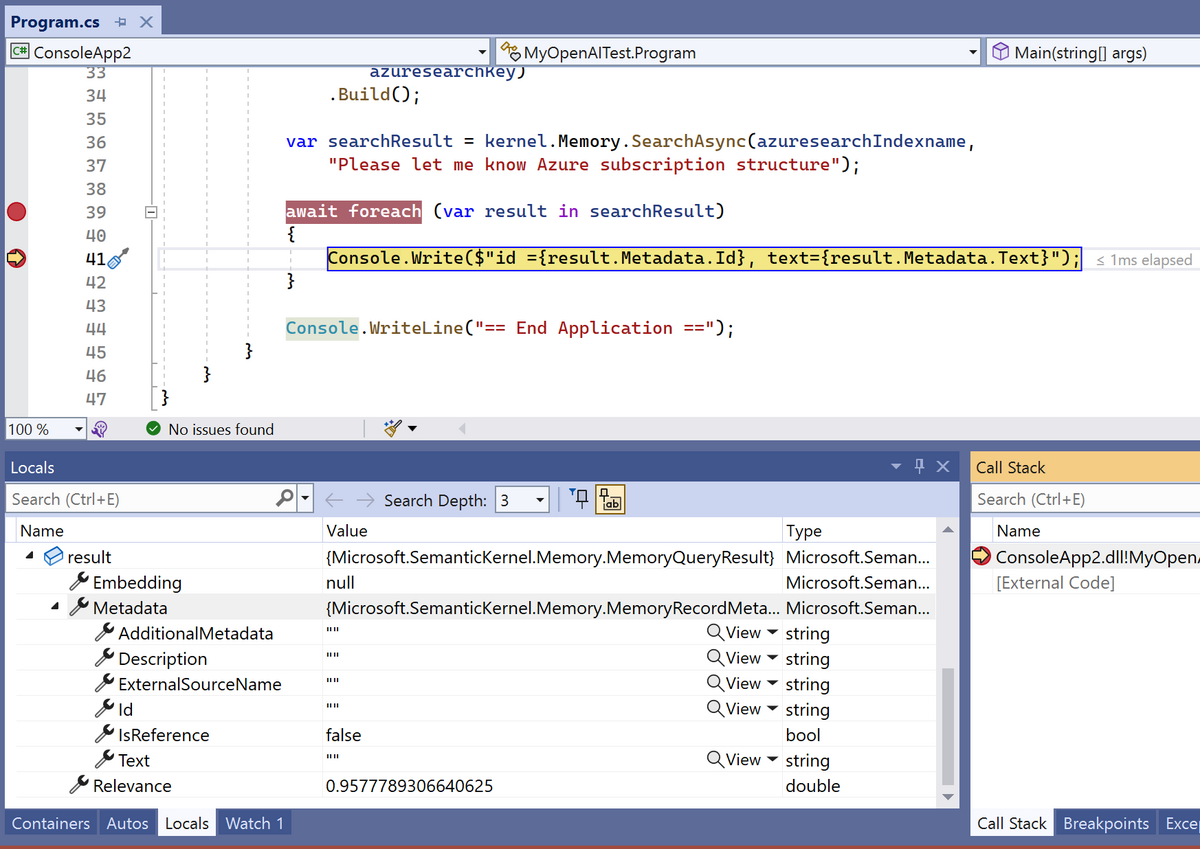
+ FullyQualifiedErrorId : NativeCommandErrorこの理由については Entra ID 自体にアカウント情報を見に行けば問題は解決します。以下の様に #EXT#@ を含む自 Entra ID テナントを付与されたものになっています。
![]()
こちらで Object ID を取得しても当然構わないのですが、念のためにコマンドで実行するとちゃんと ID が取得できることが分かります。
az ad user show --id "daichi_mycompany.com#EXT#@normalianxxxxx.onmicrosoft.com"
{
"@odata.context": "https://graph.microsoft.com/v1.0/$metadata#users/$entity",
"businessPhones": [],
"displayName": "daichi",
"givenName": null,
"id": "4bf33ec0-dc63-4468-cc7d-edd4c9820fee",
"jobTitle": "CLOUD SOLUTION ARCHITECT",
"mail": "daichi@mycompany.com",
"mobilePhone": null,
"officeLocation": null,
"preferredLanguage": null,
"surname": null,
"userPrincipalName": "daichi_mycompany.com#EXT#@normalianxxxxx.onmicrosoft.com"
}上記を利用して最初の様に az cosmosdb sql role assignment create を実行すれば割り当ては完了です。
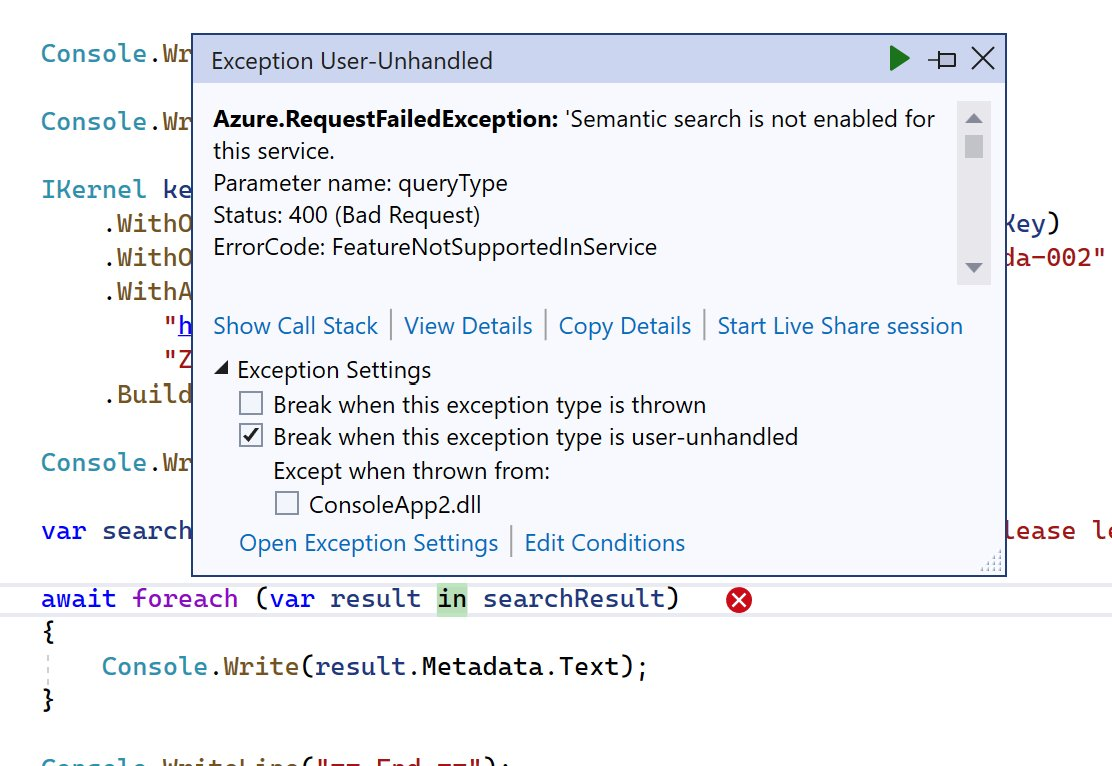
次に二つ目の開発用の Entra ID を見に行く設定を追加する必要があります。Entra ID テナントを特に指定しない場合、組織アカウントは自分が所属している Entra ID テナントの情報を取得しようとするので、今回のような「組織アカウントは本番 Entra ID、Azure サブスクリプションは開発 Entra ID」の場合には以下のようなエラーが出力されます(例は ASP.NET Core の場合)。
![]()
こちらを回避するためには C#側のソースコードで以下の様に Tenant ID を指定することで対応が可能です。
using Azure.Identity;
using Microsoft.Azure.Cosmos;
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddControllersWithViews();
builder.Services.AddSingleton<CosmosClient>(serviceProvider =>
{
var option =new DefaultAzureCredentialOptions()
{
TenantId ="your-entraid-tenant-id",
};
returnnew CosmosClient(
accountEndpoint: builder.Configuration["AZURE_COSMOS_DB_NOSQL_ENDPOINT"]!,
tokenCredential:new DefaultAzureCredential(option)
);
});
var app = builder.Build();
こちらで Entra ID テナントを指定すればアクセスが可能になるはずです。
EntraID テナントに guest 招待されたマイクロソフトアカウントを利用するケース(これも上手くいくケース)
このケースは実は guest invitation と考えは同じです。図に表すと以下になります。
![]()
以下の様に #EXT#@ を含む自 Entra ID テナントを付与されたユーザ名を指定して az ad user show コマンドを実行(または当該 Entra ID のユーザを見に行く)し、カスタムロールを割り当てる az cosmosdb sql role assignment create を実行しましょう。
az ad user show --id "warito_abnormal_hotmail.com#EXT#@normalianxxxxx.onmicrosoft.com"
{
"@odata.context": "https://graph.microsoft.com/v1.0/$metadata#users/$entity",
"businessPhones": [],
"displayName": "Daichi",
"givenName": "Daichi",
"id": "94bfd636-b2e9-4d44-b895-8d51277e7abe",
"jobTitle": "Principal Normal",
"mail": null,
"mobilePhone": null,
"officeLocation": null,
"preferredLanguage": null,
"surname": "Isamin",
"userPrincipalName": "warito_abnormal_hotmail.com#EXT#@normalianxxxxx.onmicrosoft.com"
}
az cosmosdb sql role assignment create -a $cosmosdbName -g $rgName -p "your-user-object-resourceid" -d "your-customrole-resourceid" -s "/"
{
"id": "/subscriptions/your-subscription-id/resourceGroups/your-resource-group-name/providers/Microsoft.DocumentDB/databaseAccounts/your-cosmosdb-name/sqlRoleAssignments/7adc585c-
74d6-4979-a3ed-3d968de2d27e",
"name": "7adc585c-74d6-4979-a3ed-3d968de2d27e",
"principalId": "b0bde25a-d588-410c-a16d-30fc001961c4",
"resourceGroup": "your-resource-group-name",
"roleDefinitionId": "/subscriptions/your-subscription-id/resourceGroups/your-resource-group-name/providers/Microsoft.DocumentDB/databaseAccounts/your-cosmosdb-name/sqlRoleDefinit
ions/7adc585c-74d6-4979-a3ed-3d968de2d27e",
"scope": "/subscriptions/your-subscription-id/resourceGroups/your-resource-group-name/providers/Microsoft.DocumentDB/databaseAccounts/your-cosmosdb-name",
"type": "Microsoft.DocumentDB/databaseAccounts/sqlRoleAssignments"
}EntraID テナントに Service Principal を作って利用するケース(これは上手くいかないケース)
色んなパターンを並べたので、そろそろ「めんどくせぇ!だったら開発用の Entra ID テナントで Service Principal を作ってやんよ!」と思った人もいるでしょう。これは図に表すと以下になりますが、実はこれは上手くいきません。
![]()
ちなみに Service Principal の Client ID と Object ID は異なりますので注意が必要ですが、コマンドを実行すると以下の様になります。
$ az cosmosdb sql role assignment create -a $cosmosdbName -g $rgName -p "your-serviceprincipal-clientied" -d "your-customrole-resourceid" -s "/"
az : ERROR: (BadRequest) The provided principal ID ["your-serviceprincipal-clientied"] was not found in the AAD tenant(s) [b4301d50-52bf-43f0-bfaa-915234380b1a] which are associated
with the customer's subscription.
At line:1 char:1
+ az cosmosdb sql role assignment create -a $cosmosdbName -g $rgName -p ...
+ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+ CategoryInfo : NotSpecified: (ERROR: (BadRequ...s subscription.:String) [], RemoteException
+ FullyQualifiedErrorId : NativeCommandError
ActivityId: b1b3a860-c244-11ee-9296-085bd676b6c2, Microsoft.Azure.Documents.Common/2.14.0, Microsoft.Azure.Documents.Common/2.14.0, Microsoft.Azure.Documents.Common/2.14.0,
Microsoft.Azure.Documents.Common/2.14.0, Microsoft.Azure.Documents.Common/2.14.0, Microsoft.Azure.Documents.Common/2.14.0
Code: BadRequest
Message: The provided principal ID ["your-serviceprincipal-clientied"] was not found in the AAD tenant(s) [b4301d50-52bf-43f0-bfaa-915234380b1a] which are associated with the
customer's subscription.
ActivityId: b1b3a860-c244-11ee-9296-085bd676b6c2, Microsoft.Azure.Documents.Common/2.14.0, Microsoft.Azure.Documents.Common/2.14.0, Microsoft.Azure.Documents.Common/2.14.0,
Microsoft.Azure.Documents.Common/2.14.0, Microsoft.Azure.Documents.Common/2.14.0, Microsoft.Azure.Documents.Common/2.14.0
$ az cosmosdb sql role assignment create -a $cosmosdbName -g $rgName -p "your-serviceprincipal-objectid" -d "your-customrole-resourceid" -s "/"
az : ERROR: (BadRequest) The provided principal ID ["your-serviceprincipal-objectid"] was found to be of an unsupported type : [Application]
At line:1 char:1
+ az cosmosdb sql role assignment create -a $cosmosdbName -g $rgName -p ...
+ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+ CategoryInfo : NotSpecified: (ERROR: (BadRequ...: [Application]:String) [], RemoteException
+ FullyQualifiedErrorId : NativeCommandError
ActivityId: f24dccfd-c244-11ee-9712-085bd676b6c2, Microsoft.Azure.Documents.Common/2.14.0, Microsoft.Azure.Documents.Common/2.14.0, Microsoft.Azure.Documents.Common/2.14.0,
Microsoft.Azure.Documents.Common/2.14.0, Microsoft.Azure.Documents.Common/2.14.0, Microsoft.Azure.Documents.Common/2.14.0
Code: BadRequest
Message: The provided principal ID ["your-serviceprincipal-objectid"] was found to be of an unsupported type : [Application]
ActivityId: f24dccfd-c244-11ee-9712-085bd676b6c2, Microsoft.Azure.Documents.Common/2.14.0, Microsoft.Azure.Documents.Common/2.14.0, Microsoft.Azure.Documents.Common/2.14.0,
Microsoft.Azure.Documents.Common/2.14.0, Microsoft.Azure.Documents.Common/2.14.0, Microsoft.Azure.Documents.Common/2.14.0上記で分かる通り、Service Principal の Client ID を指定すると「そもそもそんな ID ないぞ」と怒られます(ここは object id を指定していないから当たり前)。次に Object ID を指定すると「Application に割り振るのは unsupport なんじゃい!」と怒られます。ご注意を。
異なるEntraID テナント向けに複数のアカウントを利用している(上手くいくが設定が必要なケース)
こちらは複数プロジェクトを掛け持ちしている場合等に良くあるパターンではないでしょうか。今回では以下の例を想定しましょう。念のためですがマイクロソフトアカウントをアレコレ開発に用いるのは本来は非推奨なのでご注意を。
- プロジェクト①のアカウント:myuser@normalian.xxx - 会社の組織アカウント
- プロジェクト②のアカウント:personalxxxx@outlook.com - 暫定的に割り当てられたマイクロソフトアカウント
![]()
こちらを解決するには DefaultAzureCredential を利用する認証情報の優先順位を確認する必要があります。詳細はこちらを参照下さい。
learn.microsoft.com
今回の場合は AzureCliCredential つまり Azure Cliの認証を使ってアカウントを切り替えたいと思います。まずは以下のコマンドを実行します。
az login
ブラウザが起動して利用するアカウントを選ぶ必要があるので、当該アカウントを選択します。次に C#側のソースコードで以下の例を参考に、他の優先順位の高い認証情報を利用しない設定をすることで対応可能です。
using Azure.Identity;
using Microsoft.Azure.Cosmos;
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddControllersWithViews();
builder.Services.AddSingleton<CosmosClient>(serviceProvider =>
{
var option =new DefaultAzureCredentialOptions()
{
ExcludeEnvironmentCredential =true,
ExcludeWorkloadIdentityCredential =true,
ExcludeManagedIdentityCredential =true,
ExcludeSharedTokenCacheCredential =true,
ExcludeVisualStudioCredential =true,
ExcludeVisualStudioCodeCredential =true,
TenantId ="your-entraid-tenant-id",
};
returnnew CosmosClient(
accountEndpoint: builder.Configuration["AZURE_COSMOS_DB_NOSQL_ENDPOINT"]!,
tokenCredential:new DefaultAzureCredential(option)
);
});